前言
自开发Linux系统下的自动化工具开始,我逐步接触到Big Data相关的知识。2018年开始,参与了运维大数据的开发和管理,其中涉及了业界流行的spark、kafka、zookeeper、druid、hbase和hive等技术。早期自研自动化工具(详见“tools”博文)对数据分析和处理积累的经验,为这个项目打下了一个较坚实的基础,对上亿的数据处理、分析、呈现也有了一个清晰的整体认识。
正文
数据源
无论是什么程序,必然会有此程序的日志,日志可能是富文本,二进制和普通文本,而这些日志里面包含了大量数据,可以对如下方面做出分析,另外如果可以给程序方维护提要求,加入相关的数据,那么可以采集出更有效的内容。
- 系统健康状况监控
- 查找故障根源
- 系统瓶颈诊断和调优
- 追踪安全相关问题
常见数据分析
- 维度
- 时间
- 地理区域
- 指标
- 业务层面 如视频业务的点播量
- 应用层面,如每个应用的错误率,错误码,访问的平均耗时,最大耗时
- 系统资源层面:如cpu、内存、swap、磁盘、load、主进程存活
- 网络层面: 如丢包率、流量、tcp连接数
架构设计
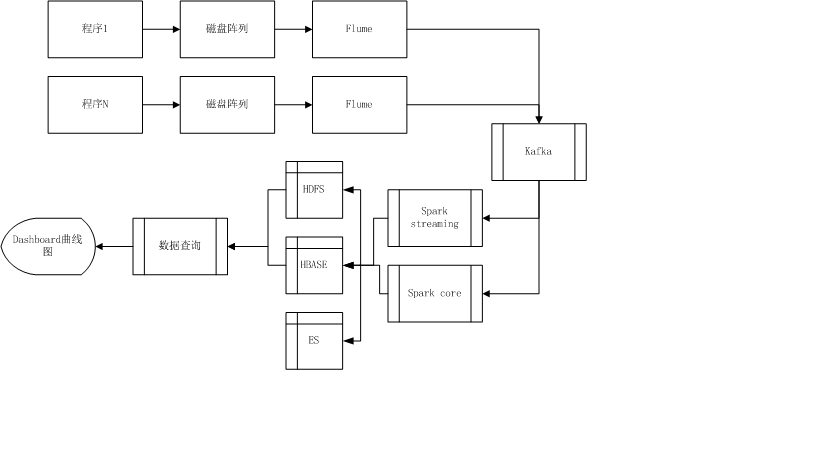
数据流设计
- 程序的日志数据存入磁盘阵列
- flume作为日志采集的agent,将日志送入kafka,定义这里的程序的topic
- kafka定义spark streaming或者core处理的topic,并通过配置文件关联这两个topic,这里引入Zookeeper作为一个资源管理库,对节点进行协调、通信、失败处理、节点损坏的处理
- 对不同的数据应用场景采用对应的处理方式,如实时性要求高的采用spark streaming 流处理,需要对整体数据进行处理的采用spark core 批处理 -数据的处理包含数据过滤,数据清洗,数据防倾斜、格式化和指标运算,处理后根据不同的业务需要进行存储
- 需要进行指标运算后的数据存入HBASE,其他数据存入HDFS,ES可以作为一个全量存储保存格式化后的所有的数据以供临时的查询分析使用。数据存储采用二级存储的机制,7天内频繁变化的数据放入HBASE,7天后将这些数据存入HDFS作为存量数据
- 通过druid对处理后的数据进行维度和指标的定义,然后关联对应的topic进行数据提取
- dashboard曲线图呈现的部分,可以采用echarts二次开发,或者使用vue等工具进行开发前文提到的常见数据分析的维度和指标,进行最终的数据的可视化。
业务流设计
这里以智能家居为例描述一个典型的业务流。
- 分析智能家居的典型业务场景,梳理这些业务场景下常用分析维度和指标
- 针对上诉分析和梳理得到的结果,进行应用程序的数据接入,无数据的部分需要应用程序提供
- 数据接入按照数据流设计的思路进行接入
- 初始的应用程序数据比较少,一般情况下需要汇聚一段时间才能进行有效的分析,也可以采用历史数据的手动输入使得数据在短时间内满足汇聚的要求
- 数据汇聚后,观察dashboard的数据图表,对分析维度和指标这些图进行分析是否能够满足业务的要求,有针对性的调整
- 有了有效的数据后,就可以加入指标数据告警和基于时间序列的智能告警,来对业务进行闭环的反馈和监控。
大数据涉及的东西很多,基本上需要自己开发的系统比较少,从日志收集,到日志存储,到结果存储等,都可以采用开源的组件,而且这些组件都支持集群模式,没有单点故障,支持可水平扩展,数据流和业务流多了,加机器就能满足。而对这些组件的深入研究就是后话了,且按下不表。