前言
本文是接上一篇VFS的姊妹篇,这次接着讲下应用程序是怎么使用文件的。
正文
图还是这张:
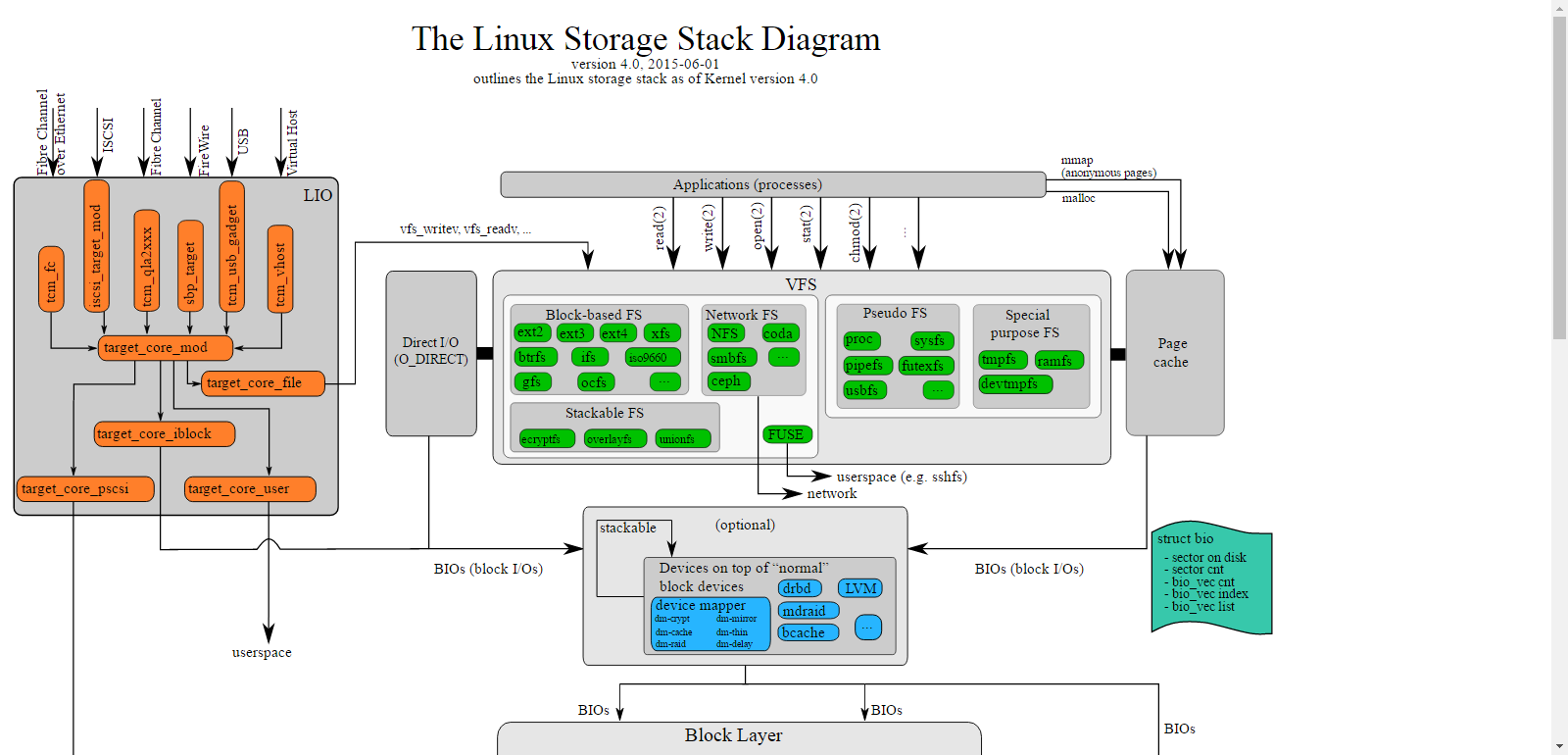 VFS related
VFS related
从上一篇我们知道了应用程序通过read/write等通用的系统调用访问文件系统,network,ram,USB等。
常见系统IO API
Linux的这些API都遵循了POSIX标准(Portable Operating System Interface),通过libc发布出来。 kernel层面的代码解读以open 这个IO操作为例:
fs.h里面声明如下:
int (*open) (struct inode *, struct file *);
但是通常我们使用的open API函数可不是这样,而是下面这样:
int open(const char *pathname, int flags, mode_t mode);
实际上Linux是通过SYSCALL_DEFINE这个宏来定义所有的系统调用,fs.h里面的接口实际上是更底层的调用,是直接对inode的操作。 open API的定义在fs/open.c里面,贴上来:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
why是这个?第一个参数啊,:D, 相信你应该猜到这个短小的函数里面干活的主要是do_sys_open,那前面的if是什么?O_LARGEFILE?force_o_largefile是一个宏定义如下:
#ifndef force_o_largefile
#define force_o_largefile() (BITS_PER_LONG != 32)
#endif
// we use include/asm-generic/bitsperlong.h to show the logic
#ifdef CONFIG_64BIT
#define BITS_PER_LONG 64
#else
#define BITS_PER_LONG 32
#endif /* CONFIG_64BIT */
看到这里就比较清楚了这个宏定义返回bool值,返回true或者false取决于cpu架构64位还是32位。拿常用的x86_64来说这里返回true,对应的flags就会加上O_LARGEFILE,看下面的定义可以看出这个和CPU架构是有关。
1 F d O_LARGEFILE arch/alpha/include/uapi/asm/fcntl.h
2 F d O_LARGEFILE arch/arm/include/uapi/asm/fcntl.h
3 F d O_LARGEFILE arch/arm64/include/uapi/asm/fcntl.h
10 F d O_LARGEFILE include/uapi/asm-generic/fcntl.h
API中对这个的flag描述如下:
O_LARGEFILE (LFS) Allow files whose sizes cannot be represented in an off_t (but can be represented in an off64_t) to be opened. The _LARGEFILE64_SOURCE macro must be defined (before including any header files) in order to obtain this definition. Setting the _FILE_OFFSET_BITS feature test macro to 64 (rather than using O_LARGEFILE) is the preferred method of accessing large files on 32-bit systems (see feature_test_macros(7)).
从这个描述可以大概知道这个是用来控制在32位系统下打开大文件的bit位,以x86_64为例,open这个系统调用在正式开工干活前,会打开大文件bit位。多大文件算大文件呢?Linux里面定义的大文件是指那些超过2^63 bytes长度的文件。
至此,我们已经搞清楚了if这个逻辑,那么现在我们来看看这个干活的function,同样在open.c里面定义:
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}
flags
正如开篇所说,flags是作为使用open系统调用的第二个参数传入,用来控制文件的打开方式;mode是第三个参数是文件的权限。do_sys_open这个函数开篇调用了build_open_flags,这里详解下这个函数:
static inline int build_open_flags(int flags, umode_t mode, struct open_flags *op)
{
int lookup_flags = 0;
int acc_mode = ACC_MODE(flags);
if (flags & (O_CREAT | __O_TMPFILE))
op->mode = (mode & S_IALLUGO) | S_IFREG;
else
op->mode = 0;
/* Must never be set by userspace */
flags &= ~FMODE_NONOTIFY & ~O_CLOEXEC;
/*
* O_SYNC is implemented as __O_SYNC|O_DSYNC. As many places only
* check for O_DSYNC if the need any syncing at all we enforce it's
* always set instead of having to deal with possibly weird behaviour
* for malicious applications setting only __O_SYNC.
*/
if (flags & __O_SYNC)
flags |= O_DSYNC;
if (flags & __O_TMPFILE) {
if ((flags & O_TMPFILE_MASK) != O_TMPFILE)
return -EINVAL;
if (!(acc_mode & MAY_WRITE))
return -EINVAL;
} else if (flags & O_PATH) {
/*
* If we have O_PATH in the open flag. Then we
* cannot have anything other than the below set of flags
*/
flags &= O_DIRECTORY | O_NOFOLLOW | O_PATH;
acc_mode = 0;
}
op->open_flag = flags;
/* O_TRUNC implies we need access checks for write permissions */
if (flags & O_TRUNC)
acc_mode |= MAY_WRITE;
/* Allow the LSM permission hook to distinguish append
access from general write access. */
if (flags & O_APPEND)
acc_mode |= MAY_APPEND;
op->acc_mode = acc_mode;
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
if (flags & O_CREAT) {
op->intent |= LOOKUP_CREATE;
if (flags & O_EXCL)
op->intent |= LOOKUP_EXCL;
}
if (flags & O_DIRECTORY)
lookup_flags |= LOOKUP_DIRECTORY;
if (!(flags & O_NOFOLLOW))
lookup_flags |= LOOKUP_FOLLOW;
op->lookup_flags = lookup_flags;
return 0;
}
这个里面有几个概念需要说一下
int acc_mode = ACC_MODE(flags)
ACC_MODE是一个宏
#define ACC_MODE(x) ("\004\002\006\006"[(x)&O_ACCMODE])
#define O_ACCMODE 0003
这个的定义很有意思,”\004\002\006\006”等价于{‘\004’, ‘\002’, ‘\006’, ‘\006’},那么这个宏的展开值就取决于(x)&O_ACCMODE得到的索引,我们使用的read, write已经read/write权限定义如下:
#define O_RDONLY 00
#define O_WRONLY 01
#define O_RDWR 02
通过这样的计算得到ACC_MODE,获取文件的读写等权限,实际上了解这些数字的同学看到上面的那个数组,应该就会意吧,4, 2,6不正我们在Linux系统管理的时候用来修改文件权限的么。
下面这段处理则是用于获得打开文件的时候权限:
if (flags & (O_CREAT | __O_TMPFILE))
op->mode = (mode & S_IALLUGO) | S_IFREG;
else
op->mode = 0;
kernel的代码可阅读性很强,从字面就可以知道O_CREAT或者__O_TMPFILE大概是什么意思。这两个宏就是我们在使用open 系统调用的时候会传入的flags,如果这两者都不是,则被忽略掉,mode赋为初始值。
下一步会去检查这个文件是否通过fanotify的打开,并且flag不是O_CLOEXEC。
/* Must never be set by userspace */
flags &= ~FMODE_NONOTIFY & ~O_CLOEXEC;
默认的情况下,新的文件描述符会保持打开当同时使用execve系统调用,但是open这个系统调用可以支持O_CLOEXEC这个flag来改变这个默认的行为。这里的情况是针对这样的场景:当父进程打开一个文件并且flag是O_CLOEXEC,同时fork出来的子进程执行execve系统调用,因为子进程会继承父进程的文件描述符,通过这种方式可以防止丢失文件描述符。
接着,检查flags里面是否有O_SYNC flag,应用O_DSYNC flag。
if (flags & __O_SYNC)
flags |= O_DSYNC;
__O_SYNC保证了任何写入的系统调用在所有数据传递到磁盘后才会返回。O_DSYNC和它有些类似,区别在于O_DSYNC会对元数据的进行更新,但是对于open系统调用来说使用__O_SYNC 就可以了,因为kernel已经实现了__O_SYNC|O_DSYNC。
下一步是和临时文件有关,如果用户想要创建一个临时文件,那么flags必须有O_TMPFILE_MASK,或者有O_TMPFILE,而且是可写的
if (flags & __O_SYNC)
flags |= O_DSYNC;
if (flags & __O_TMPFILE) {
if ((flags & O_TMPFILE_MASK) != O_TMPFILE)
return -EINVAL;
if (!(acc_mode & MAY_WRITE))
return -EINVAL;
} else if (flags & O_PATH) {
/*
* If we have O_PATH in the open flag. Then we
* cannot have anything other than the below set of flags
*/
flags &= O_DIRECTORY | O_NOFOLLOW | O_PATH;
acc_mode = 0;
}
正如在Linux的系统调用里面所说:
O_TMPFILE must be specified with one of O_RDWR or O_WRONLY and, optionally, O_EXCL. http://man7.org/linux/man-pages/man2/open.2.html
如果没有传递创建临时文件的操作,下一步就开始检查O_PATH flag,这个flag有两个目的:
1.表明文件所在位置在整个文件系统树里(这不是废话么。。。)
2.所做操作完全基于文件描述符的级别
所以在这种情况下,如果文件本身没有打开,诸如dup,fcntl 等其他操作也可以使用,和文件内容有关的操作读,写等也是可以的,flags只有O_DIRECTORY | O_NOFOLLOW | O_PATH,至此op->open_flag的值就完成了。
op->open_flag = flags
现在我们已经填完了open_flag这个字段,现在我们来看看mode。
/* O_TRUNC implies we need access checks for write permissions */
if (flags & O_TRUNC)
acc_mode |= MAY_WRITE;
/* Allow the LSM permission hook to distinguish append
access from general write access. */
if (flags & O_APPEND)
acc_mode |= MAY_APPEND;
在前面我们已经对acc_mode 有过赋值的情况下,这里还有最后两步。flag O_TRUNC会把打开的文件截断为长度0,在我们使用open之前, 而O_APPEND则打开文件的追加模式,这样在写入的时候不是覆盖而是追加内容。 接着是intent这个字段,这个字段记录的是我们是对文件打开,创建,重命名还是其他操作,如果我们的flags包涵O_PATH则intent为0,表明我们不做任何和文件内容有关的事情。
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
或者是LOOKUP_OPEN
if (flags & O_CREAT) {
op->intent |= LOOKUP_CREATE;
if (flags & O_EXCL)
op->intent |= LOOKUP_EXCL;
}
这段的意思是如果我们创建一个新文件的时候,intent 会被加上LOOKUP_CREATE,这时如果flags又有O_EXCL则再加上LOOKUP_EXCL。
最后是对lookup_flags的赋值:
if (flags & O_DIRECTORY)
lookup_flags |= LOOKUP_DIRECTORY;
if (!(flags & O_NOFOLLOW))
lookup_flags |= LOOKUP_FOLLOW;
op->lookup_flags = lookup_flags;
这段也比较好理解,第一个判断是针对目录和符号链接的,相关的解释在此就不再赘述。到这里build_open_flags 就结束了,open_flags相关的字段也已经填写完毕,现在我们回到do_sys_open
真正的open
经过上面的处理,我们已经有了flags和mode,接着我们通过getname这个函数得到filename结构体,如果c也有类的话,这里可以叫做一个实例吧。参数就是我们在进行open系统调用的时候传入的filename字符串。
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
struct filename *
getname(const char __user * filename)
{
return getname_flags(filename, 0, NULL);
}
getname_flags的实现比较长,这里就不贴了,这个函数主要的功能是把文件路径从user space 拷贝到kernel space,filename的结构体定义在include/linux/fs.h:
struct filename {
const char *name; /* pointer to actual string */
const __user char *uptr; /* original userland pointer */
struct audit_names *aname;
int refcnt;
const char iname[];
};
-name: 指向文件路径的指针,内核空间
- uptr: 注释很详细了,:)
- aname: 从audit上下文得到的文件名
- refcnt:索引计数
- iname: 文件名
当文件名被传递到内核空间后,获取一个新的文件描述符
fd = get_unused_fd_flags(flags);
get_unused_fd_flags这个函数根据flags、当前进程打开的文件fd tables和文件描述符的范围(从0~RLIMIT_NOFILE)这三个方面获取文件描述符,获取成功后在当前进程的fd tables里面置该文件描述符为busy。 get_unused_fd_flags也会对O_CLOEXEC这一flag进行设置或者清除
__set_open_fd(fd, fdt);
if (flags & O_CLOEXEC)
__set_close_on_exec(fd, fdt);
else
__clear_close_on_exec(fd, fdt);
error = fd;
#if 1
/* Sanity check */
if (rcu_access_pointer(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL);
}
#endif
这里多贴了点,因为没想到内核也有#if 1/#endif这种调试代码,哈哈。 最后也就是最主要的活是在do_sys_open里的do_filp_open实现里面。
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd;
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}
这个功能主要就是根据给定的文件路径填充file这个结构体,函数一开始初始化nameidata,这个结构体提供一个指向文件inode的指针,也就是通过文件名获取到inode,接着path_openat被调用,注意到这个函数可能会被调用三次:第一次是以RCU模式打开,这种方式是最有效的方式,失败后则会尝试通过normal的方式打开,,第三次这是尝试REVAL模式也就是相对rare的方式,而path_openat这进行路径的查找,获得这个文件的目录信息,这个里面有个重要的调用就是do_last,这个函数最终会执行vfs_open函数
int vfs_open(const struct path *path, struct file *file, const struct cred *cred)
vfs_open主要的功能就是根据path,file去执行open,而这个open就是我们开篇提到的。
OK, 到此基本上我们撸通open的整个kernel实现过程,当然我们跳过了很多细节,尤其是那些不是generic实现的open系统调用诸如arm64等其他,读者如果有兴趣可以去查看相关的代码。
总结
很多情况下我们使用Linux系统调用的时候,需要考虑性能,这时可以使用dd这个工具去测试当前系统IO的性能。关于文件IO的部分就讲到这,有疑问的朋友欢迎访问我的知乎,linked-in和我探讨,当然也可以申请一个disqus账号直接在本文下留言讨论。